马尔可夫决策过程
马尔可夫决策过程
马尔可夫性质
The future is independent of the past given the present
定义
状态 St 是马尔可夫的,当且仅当 P[St+1∣St]=P[St+1∣S1,...,St]。
(St=f(Ht))
性质
- 状态从历史中捕获到了所有相关信息
- 当状态已知的时候,可以抛开历史不管
- i.e. 当前状态是未来的充分统计量
MDP 五元组
MDP可以由一个五元组表示:(S,A,{Psa},γ,R)
S 是状态的集合。比如:迷宫中的为止,Atari 游戏中的当前屏幕显示
A 是动作的集合。比如:像上下左右四个方向移动,手柄操纵杆的方向和按钮
Psa 是状态转移概率。
γ∈[0,1] 是对未来奖励的折扣因子
R:S×A↔R 是奖励函数。有时奖励只与状态相关
MDP 的动态
MDP 的动态如下表示:
- 从状态 s0 开始
- 智能体选择某个动作 a0∈A
- 智能体得到奖励 R(s0,a0)
- MDP 随机转移到下一个状态 s1∼Ps0a0
这个过程不断进行:s0a0,R(s0,a0)s1a1,R(s1,a1)a2a2,R(s2,a2)s3⋯
直到终止状态 ST 出现为止,或者无止尽地进行下去
智能体的总回报为:R(s0,a0)+γR(s1,a1)+γ2(s2,a2)+⋯
基于动态规划的强化学习
MDP 目标和策略
目标
选择能够最大化累积奖励期望的动作:E[R(s0)+γR(s1)+γ2R(s2)+⋯]
(所有的这些奖励都可能是随机的,故此处采用期望)
γ∈[0,1] 表示未来奖励的折扣因子,使得和未来奖励相比起来智能体更重视即时奖励
(以金融为例,今天的¥1 比明天的¥1 更有价值)
策略
给定一个特定的策略:π(s):S→A,即在状态 s 下采取动作 a=π(s)
给策略 π 定义价值函数:Vπ(s)=E[R(s0)+γR(s1)+γ2R(s2)+⋯∣s0=s,π],即给定其实状态和根据策略 π 采取动作时的累积奖励期望
价值函数的 Bellman 等式
给策略 π 定义价值函数公式中的 γR(s1)+γ2R(s2)+⋯ 项可以写成 γVπ(s1)。
因此可以得到 Bellman 等式:Vπ(s)=R(s)+γs′∈S∑psπ(s)(s′)Vπ(s′)
- R(s) 即时奖励
- psπ(s′) 状态转移概率
- Vπ(s′) 下一个状态的价值
最优价值函数
对于状态 s 来说的最优价值函数是所有策略可获得的最大可能折扣奖励和
V∗(s)=πmaxVπ(s)
最优价值函数的 Bellman 等式
V∗(s)=R(s)+a∈Amaxγs′∈S∑psa(s′)V∗(s′)
最优策略
π∗(s)=arga∈Amaxs′∈S∑psa(s′)V∗(s′)
对状态 s 和策略 π
V∗(s)=Vπ∗(s)≥Vπ(s)
价值迭代和策略迭代
价值函数和策略相关
Vπ(s)=R(s)+γs′∈S∑psπ(s)(s′)Vπ(s′)
π(s)=arga∈Amaxs′∈S∑psa(s′)Vπ(s′)
可以对最优价值函数和最优策略执行迭代更新
价值迭代
对于一个动作空间和状态空间有限(∣S∣<∞,∣A∣<∞)的 MDP
价值迭代过程
对每个状态 s,初始化 V(S)=0
重复一下过程直到收敛
- 对每个状态,更新 V(s)=R(s)+a∈Amaxγs′∈S∑psa(s′)V(s′)
注意:以上计算中没有明确的策略
同步 vs. 异步价值迭代
同步的价值迭代会储存两份价值函数的拷贝
对 S 中的所有状态 s
Vnew(s)←a∈Amax(R(s)+γs′∈S∑psa(s′)Vold(s′))
更新 Vold(s)←Vnew(s)
异步价值迭代值只储存一份价值函数
- 对 S 中的所有状态 s:V(s)←a∈Amax(R(s)+γs′∈S∑psa(s′)V(s′))
策略迭代
对于一个动作空间和状态空间有限(∣S∣<∞,∣A∣<∞)的 MDP
策略迭代过程
随机初始化策略 π
重复一下过程直到收敛
- 让 V←Vπ(特别耗时)
- 对每个状态,更新 arga∈Amaxs′∈S∑psa(s′)V(s′)
更新价值函数会很耗时
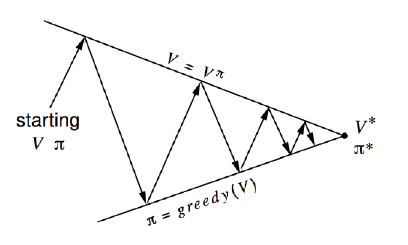
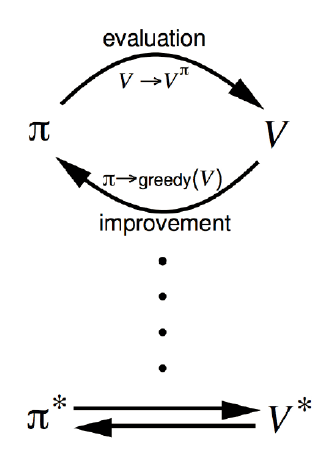
策略评估
策略改进
- 生成 π′≥π
- 贪心策略改进
总结
- 价值迭代是贪心更新法
- 策略迭代中,用 Bellman 等式更新价值函数的代价很大
- 对于空间较小的 MDP,策略迭代通常很快收敛
- 对于空间较大的 MDP,价值迭代更实用(效率更高)
- 如果没有状态转移循环,最好使用价值迭代
基于模型的强化学习
学习一个 MDP 模型
目前我们关注在给定一个已知 MDP 模型后(状态转移函数 Psa(s′) 和奖励函数 R(s) 明确给定后)
但是,在实际问题中,状态转移和奖励函数一般不是明确给出的。
比如,我们只看到了一些 episodes(采样):
Episode1: s0(1)a0(1),R(s0)(1)s1(1)a1(1),R(s1)(1)s2(1)⋯sT(1)
Episode2: s0(2)a0(2),R(s0)(2)s1(2)a1(2),R(s1)(2)s2(2)⋯sT(2)
从“经验”中学习一个 MDP 模型
- 学习状态转移概率 Psa(s′) = 在 s 下采取动作 a 并转移到 s′ 的次数 ÷ 在 s 下采取动作 a 的总次数
- 学习奖励函数 R(s),也就是立即奖赏期望 R(s)=average[R(s)(i)]
另一种解决方式是不学习 MDP,直接从经验中学习价值函数和策略
学习模型 & 优化策略
算法思路
- 随机初始化策略 π
- 重复以下过程直到收敛
- 在 MDP 中执行 π 进行一些测验
- 使用 MDP 中的累积经验更新 Psa 和 R 的估计
- 利用 Psa 和 R 的估计执行价值迭代,得到新的估计价值函数 V
- 根据 V 更新策略为 π 为贪心策略




