MARL 简介
强化学习:智能体与环境交互,智能体感知环境结果,做出动作,得到环境反馈的奖励。
环境要是稳态的:某些分布是确定不变的,否则不能保证强化学习的收敛性
MARL 的例子
去中心化的游戏人工智能
- 为复杂的集体游戏智能设计多智能体通信和协同学习的算法
- 英雄联盟、星际争霸等
城市交通
分拣机器人
MARL 的难点
原理上困难
- 多智能体不仅要与环境交互,还要相互进行交互
- 将其它智能体当作环境的一部分进行学习,会导致训练出的智能体不稳定!因为理论上这样定义环境不稳定(数据分布非稳态),训练过程不收敛
MARL 问题定义
环境的稳态:条件概率的分布是固定的
序贯决策的三种问题
- 马尔可夫决策过程
- 重复博弈
- 随机博弈(马尔可夫博弈)
MARL 的任务属于随机博弈
随机博弈
表格型强化学习设置下,每个状态对应一个博弈表格
每个时间步,所有智能体在当前博弈表格中同时选择自己的动作
根据智能体共同决定的博弈表格单元分配给智能体奖励
博弈根据状态和联合动作转移到下一个状态,对应另一个博弈表格
一般情况下,奖励值随时间步衰减
随即博弈的问题定义
一个随机博弈可以定义成元组 (N,S,A,R,p,γ)
- N 是智能体的数目
- S 是所有智能体的状态集合
- A=A1×A2×⋯×AN 是所有智能体的动作集合
- R=r1×r2×⋯×rN 是所有智能体的奖励函数集合
- p:S×A→Ω(S) 是环境转移的概率,其中 Ω(S) 在 S 的分布集合
- γ∈(0,1) 是奖励随时间步的衰减因子
对于一个随即博弈中的每一个智能体 i,其策略表示为:πi:S→Ω(Ai)
所有智能体的联合策略可表示为 π=[π1,⋯,πN]
所有智能体的联合动作可表示为 a=[a1,⋯,aN]
基于联合策略 π,智能体 i 在状态 s 下的价值为:Viπ(s)=∑t=0∞γtEπ,p[rit∣s0=s]
基于联合策略 π,智能体 i 在状态行动对 (s,a) 下的价值为:Qiπ(s,a)=ri(s,a)+γEs′∼p[Viπ(s′)]
MARL 方法分类
完全中心化:将所有智能体看成一个超级智能体在做决策。优点:环境是稳态 缺点:但复杂度高
完全去中心化:每个智能体都独立进行学习,不考虑其它智能体的改变。优点:简单好实现 缺点:环境非稳态,可能不收敛
中心化训练,去中心化执行:训练时使用一些单个智能体看不到的全局信息,执行时不使用这些信息。介于完全中心化和完全去中心化方法之间
完全中心化方法
整体智能体
对于合作任务,可以将 N 个智能体堪称一个大的智能体,每次在具体的状态下,直接选择联合联合动作,以每个智能体获得的奖励之和作为大智能体的奖励。
缺点:
- 动作空间太大,状态转移和奖励函数复杂度太高
- 无法处理非合作任务
纳什 Q 学习
给定联合策略,针对智能体 i 优化其状态价值函数依赖于联合策略
在随机博弈中的纳什均衡可以由一个联合策略 π∗ 来表示,使得没有任何一个智能体有动机去进一步修改其策略
Viπ∗(s)≥Vi(s,πi,π−i∗) for ∀πi
给定纳什策略 π∗,其纳什价值函数为 VNash(s)=[V1π∗(s),V2π∗(s),⋯,VNπ∗(s)]
考虑到智能体 i 在状态行动对(s,a) 下的价值为 Qiπ(s,a)=ri(s,a)+γEs′∼p[Viπ(s′)]
纳什 Q 学习进行一下两步操作,直到收敛
- 基于当前每个状态的 Q 值表,求解纳什均衡,以及每个状态的纳什价值函数
- 基于纳什价值函数,更新 Q 值表
作为一种完全中心化的方法,纳什 Q 学习的缺点
- 计算复杂度太高
- 无法处理非合作的博弈场景
完全去中心化方法
简单好实现,但是很可能不收敛
一个随机博弈可以定义成元组 (N,S,A,R,p,γ)
- N 是智能体的数目
- S=S1×S2×⋯×SN 是所有智能体的状态集合 完全去中心化的方法可以让每个智能体的局部感知状态不同。
- A=A1×A2×⋯×AN 是所有智能体的动作集合
- R=r1×r2×⋯×rN 是所有智能体的奖励函数集合
- p:S×A→Ω(S) 是环境转移的概率,其中 Ω(S) 在 S 的分布集合
- γ∈(0,1) 是奖励随时间步的衰减因子
独立 Q 学习:对智能体 i,假设其它智能体策略不变,直接 Q 学习
- 此处环境的奖励还是基于联合动作,后期会变化导致可能不收敛
独立 PPO:对智能体 i,建设其它智能体策略是不变的,直接 PPO
中心化训练,去中心化执行
aka CTDE, centralized training with decentralized execution
在训练的时候使用一些单个智能体看不到的全局信息而达到更好的训练效果,而在执行时不使用这些信息,每个智能体完全根据自己的策略直接行动,以达到去中心化执行的效果。
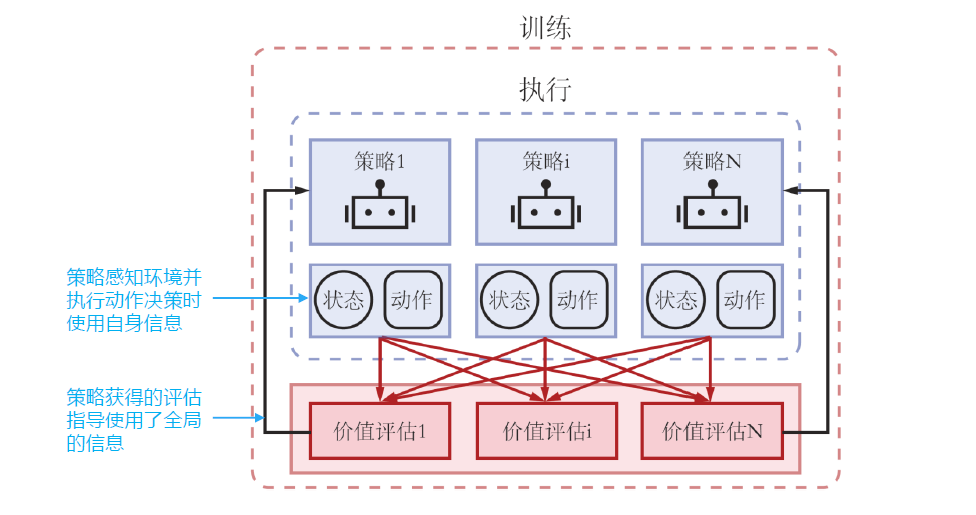
CTDE 问题建模
建模为部分可观测马尔可夫博弈元组
- N 是智能体的数目
- S 是所有智能体的状态集合
- A 是所有智能体的动作集合
- p:S×A→Ω(S) 是环境转移的概率,其中 Ω(S) 在 S 的分布集合
- γ∈(0,1) 是奖励随时间步的衰减因子
- 对于每个智能体 i
- Oi 是其关测集合
- Ai 是其动作集合
- πi:Oi→Ω(Ai)
- ri:S×A→R 是奖励函数,rit 表示在 t 时间步获得的具体奖励信号
- 目标是最大化期望累积奖励 Ri=E[∑t=0Tγtrit]
CTDE 算法:MADDPG
MADDPG
- 每个智能体 i 是一个 Actor-Critic
- Actor 策略 μi(ai∣oi) 是自己独有的,只能局部关测
- Critic 价值函数 Qiμ(x,a1,⋯,aN) 则是所有智能体贡献的,具有全局信息
- x=(o1,o2,⋯,oN) 为所有智能体的观测
对于确定性策略来说,考虑 N 个连续策略 μθ,其 DDPG 梯度公式为:
∇θiJ(μi)=Ex∼D[∇θiμi(oi)∇aiQiμ(x,a1,⋯,aN)∣ai=μi(oi)]
- 其中 D 为经验回放池,里面存储的数据单元为 (x,x′,a1,⋯,aN,r1,⋯,rN)
对于中心化的 critic 价值函数 Qωiμ(x,a1,⋯,aN) 则通过时序差分来学习。





