A3C
Actor-Critic
- 演员采取动作使评论家满意
- 评论家学会准确估计演员策略所采取动作价值的值函数
A2C
Advantage Actor-Critic
通过减去一个基线函数来优化评论家的打分
- 更多信息指导:降低较差动作概率,提高较优动作概率
- 进一步降低方差
优势函数 Aπ(s,a)=Qπ(s,a)−Vπ(s)
A3C:异步 A2C 方法
Asynchronous Advantage Actor-Critic
- 异步:算法涉及并执行一组环境
- 优势:策略梯度的更行使用优势函数
- 动作评价
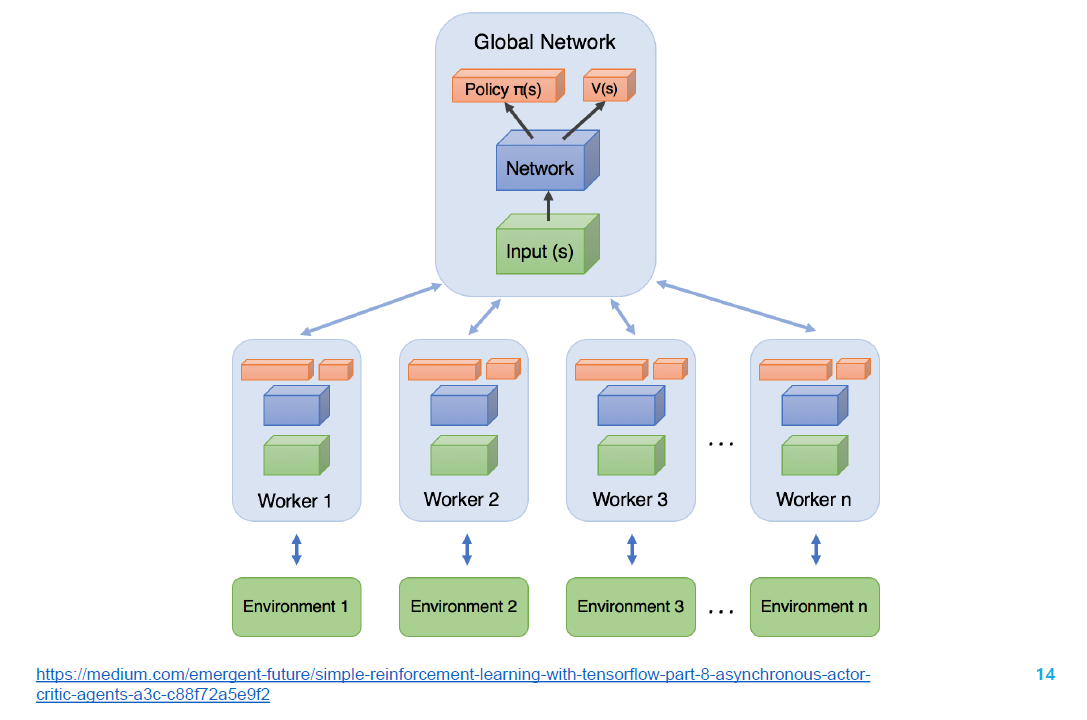
Global Network 是表演者和评论家的所在
这些 Workers 学习完一段时间后,产生梯度,传到 global network 中去。更新完全局网络后参数又同步到所有 workers 上去。这样的好处是并行化,提升性能。

确定性策略梯度 DPG
随机策略与确定性策略
- 随机策略
- 对于离散动作:π(a∣s;θ)=Σa′exp{Qθ(s,a′)}exp{Qθ(s,a)}
- 对于连续动作:π(a∣s;θ)∝exp{(a−μθ(s))2}
- 确定性策略
- 对于离散动作:π(s;θ)=argmaxaQθ(s,a) 不可微
- 对于连续动作:a=π(s;θ) 可微
确定性策略梯度
用于估计状态-动作值的评论家模块
Qw(s,a)≃Qπ(s,a)
L(w)=Es∼ρπ,a∼πθ[(Qw(s,a)−Qπ(s,a))2]
确定性策略梯度定理
J(πθ)=Es∼ρπ[Qπ(s,a)]
∇θJ(πθ)=Es∼ρπ[∇θπθ(s)∇aQπ(s,a)∣a=πθ(s)]
深度确定性梯度策略 DDPG
在 DPG 的基础上增加
- 经验重放(离线策略)
- 目标网络
- 在动作输入前对 Q 网络做 batch normalization
- 添加连续噪声
目标网络至关重要
信任区域策略优化 TRPO
策略梯度的缺点
步长难以确定:
- 采集到数据的分布会随策略的更新而变化
- 较差的步长产生的影响大,进而导致策略变差
TRPO
优化目标:策略梯度
第一种:J(θ)=Eτ∼pθ(τ)[Σtγtr(st,at)]
第二种:J(θ)=Es0∼pθ(s0)[Vπθ(s0)]
优化目标的优化量
J(θ′)−J(θ)=J(θ′)−Es0∼pθ(s0)[Vπθ(s0)]
=J(θ′)−Eτ∼pθ′(τ)[Vπθ(s0)]
=J(θ′)−Eτ∼pθ′(τ)[∑t=0∞γtVπθ(st)−∑t=1∞γtVπθ(st)]
=J(θ′)+Eτ∼pθ′(τ)[∑t=0∞γt(γVπθ(st+1)−Vπθ(st))]
=Eτ∼pθ′(τ)[∑t=0∞γtr(st,at)]+Eτ∼pθ′(τ)[∑t=0∞γt(γVπθ(st+1)−Vπθ(st))]
=Eτ∼pθ′(τ)[∑t=0∞γt(r(st,at)+γVπθ(st+1)−Vπθ(st))]
=Eτ∼pθ′(τ)[∑t=0∞γtAπθ(st,at)]
优势函数 Aπθ(st,at)=Qπθ(st,at)−Vπθ(st)
使用重要性采样
J(θ′)−J(θ)
=Eτ∼pθ′(τ)[∑t=0∞γtAπθ(st,at)]
=∑tEst∼pθ′(st)[Eat∼πθ′(at∣st)[γtAπθ(st,at)]]
=∑tEst∼pθ′(st)[Eat∼πθ′(at∣st)[πθ(at∣st)πθ′(at∣st)γtAπθ(st,at)]]
忽略状态分布的差异
当策略更新前后变化较小时,令 pθ(st)≈pθ′(st)
策略改进的单调性保证
每轮迭代都能保证函数值优化
近端策略优化 PPO
TRPO 使用 KL 散度约束策略更新的幅度
TRPO 的不足
在 TRPO 基础上进行改进
截断式优化目标
基于 CLIP 的方式,截断式优化 TRPO 中的重要性采样
优势函数选用多步时许差分
- 每次迭代中,并行 N 个 actor 收集 T 步经验数据
- 计算每步的优势函数,构成 mini-batch
- 更新参数
自适应的 KL 惩罚项参数




