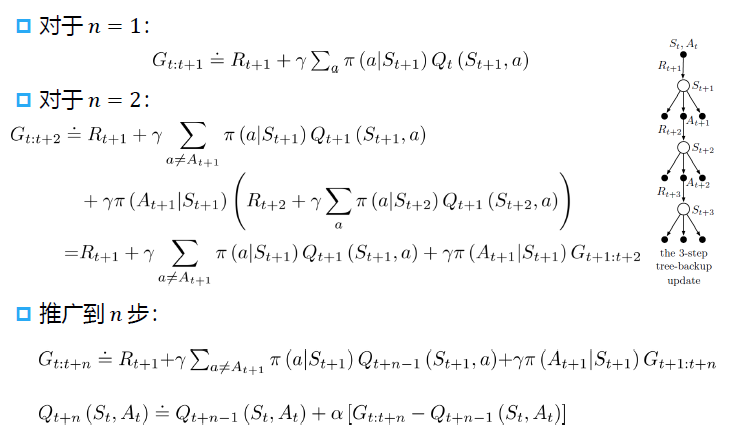SARSA
SARSA
对于当前策略执行每个(状态→动作→奖励→状态→动作)元组
SARSA 更新状态-动作值函数为:Q(s,a)←Q(s,a)+α(r+γQ(s′,a′)−Q(s,a))
使用 SARSA 的在线策略(on-policy)可控制
对于每个时间步长
- 评估策略:Q(s,a)←Q(s,a)+α(r+γQ(s′,a′)−Q(s,a))
- 策略改进:ϵ−greedy 方法
算法具体步骤
初始化 Q(s,a)
循环(for each episode)
在线策略时序差分控制(on-policy TD control)使用当前策略进行动作采样,即 SARSA 算法中的两个 Action 都是基于当前策略选择的。
Q-Learning
Q-Learning 算法及其收敛性
离线策略学习
什么是离线策略学习
- 目标策略 π(a∣s) 进行值函数评估(Vπ(s) 和 Qπ(s,a))
- 行为策略 μ(a∣s) 收集数据 {s1,a1,r1,s2,r2,a2,⋯,sT}∼μ
为什么使用离线策略学习
- 平衡探索 exploration 和利用 exploitation
- 通过观察人类或其它智能体学习策略
- 重用旧策略所产生的经验
- 遵循探索策略时学习最优策略
- 遵循一个策略时学习多个策略
Q 学习
学习状态-动作值函数 Q(s,a)∈R,不直接优化策略
是一种离线策略(off-policy)学习方法
数据有可能是通过其它策略采样得到的
Q(st,at)=∑t=0TγtR(st,at),at∼μ(st)
- 策略函数 μ(⋅∣st)∼μ(st)
- 动作空间 a∼A
- 迭代式 Q(st,at)=R(st,at)+γQ(st+1,at+1)
无需重要性采样
根据行为策略选择动作 at∼μ(⋅∣st)
根据目标策略选择后续动作 at+1′∼π(⋅∣st)
- 目标 Q∗(st,at)=rt+γQ(st+1,at+1′)
更新 Q(st,at) 的值以逼近目标状态-动作值
Q(st,at)←Q(st,at)+α(rt+1+γQ(st+1,at+1′)−Q(st,at))
使用 Q 学习的离线策略控制
允许行为策略和目标策略都进行改进
目标策略 π 是关于 Q(s,a) 的贪心策略
π(st+1)=argmaxa′Q(st+1,a′)
行为策略 μ 是关于 Q(s,a) 的 ε-greedy 策略
Q 学习目标函数可简化为
rt+1+γQ(st+1,at+1′)=rt+1+γQ(st+1,argmaxat+1′(st+1,at+1))
=rt+1+γmaxat+1′Q(st+1,at+1′)
Q 学习更新方式
Q(st,at)←Q(st,at)+α(rt+1+γmaxat+1′Q(st+1,at+1′)−Q(st,at))
Q 学习控制算法
状态 s,执行动作 a→观测到奖励 r→转移到下一状态 s’,执行动作 argmaxa′Q(s′,a′)
定理:Q 学习控制收敛到最优状态-动作值函数 Q(s,a)→Q∗(s,a)
Q 学习的收敛性证明
收缩算子 contraction operator
- Q(s,a)=r(s,a)+γmaxa′Q(s′,a′)
- 定义 H 算子:HQ=r(s,a)+γEs′∼p(⋅∣s,a)[maxa′Q(s′,a′)]
- 最优值函数 Q∗ 是 H 的不动点,意味着 Q∗=HQ∗
直接从 Q 函数证明
(Hq)(x,a)=∑y∈XPa(x,y)[r(x,a,y)+γmaxb∈Aq(y,b)]
∣∣Hq1−Hq2∣∣∞
=maxx,a∣∑y∈XPa(x,y)[γmaxb∈Aq1(y,b)+γmaxb∈Aq2(y,b)]∣
≤maxx,aγ∑y∈XPa(x,y)∣maxb∈Aq1(y,b)−maxb∈Aq2(y,b)∣
≤maxx,aγ∑y∈XPa(x,y)maxz,b∣q1(z,b)−q2(z,b)∣
=maxx,aγ∑y∈XPa(x,y)∣∣q1−q2∣∣∞
=γ∣∣q1−q2∣∣∞
可以使用柯西收敛准则证明
第 3 讲 多步自助法
多步时序差分预测
回顾动态规划和时序差分
动态规划需要知道整个 MDP 环境的状态转移和奖励函数,完全反向传播。
时序差分算法基于一步采样去做。
回顾蒙特卡洛方法和时序差分
蒙特卡洛:基于当前 state 采样后面所有步,累积奖励函数
时序差分:只走一步
那么有没有介于时序差分和蒙特卡洛的方法呢?
有,被称之为多步时序差分。
多步时序差分
比如 3-step TD。向前走三步,得到一个累积奖励值来更新
n=1 时,是 TD
1<n<∞ 时,是 n-step TD
n=∞ 时,是蒙特卡洛方法
n 步累计奖励:Gt(n)=Rt+1+γRt+2+⋯+γn−1Rt+n+γnV(St+n)
n 步时序差分学习:V(St)←V(St)+α(Gt(n)−V(St))
平均 n 步累计奖励
可以进一步对不同 n 下的 n 步累计奖励求平均值
例如求 2 步和 3 步时的平均累计奖励 21G(2)+21G(3)
使用平均 n 步累计奖励的 TD(λ) 算法
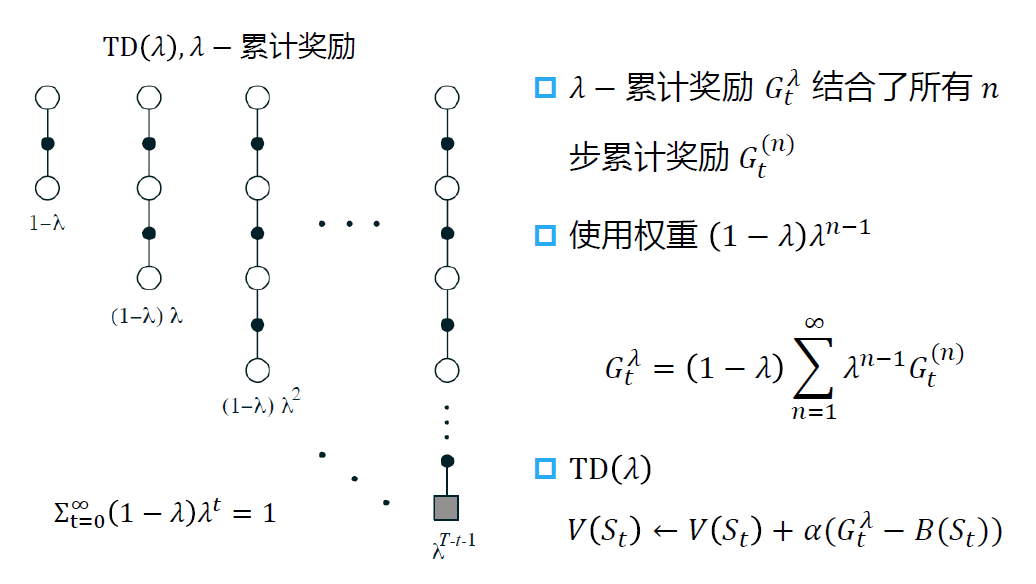
当 λ = 1 时,相当于蒙特卡洛方法
当 λ = 0 时,相当于单步时序差分
多步 SARSA
n-step 的思想用在控制上,就是多步 SARSA 算法。
使用重要性采样的多步离线学习法
对于状态值函数 V
Vt+n(St)=Vt+n−1(St)+αρt:t+n−1[Gt:t+n−Vt+n−1(St)]
ρt:h=Πk=tmin(h,T−1)b(Ak∣sk)π(Ak∣Sk)
对于动作值函数 Q:
Qt+n(St,At)=Qt+n−1(St,At)+αρt+1:t+n[Gt:t+n−Qt+n−1(St,At)]
ρt:h=Πk=tmin(h,T−1)b(Ak∣sk)π(Ak∣Sk)
多步树回溯算法
多步连乘导致方差大,为了解决这一问题,避免重要性采样。可用多步树回溯算法替代。
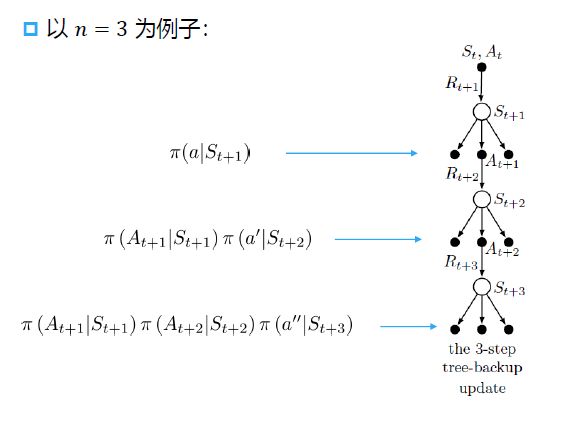
多步树回溯算法推导