

计算机视觉 W38 Convolutional Neural Networks
Convolution disadvantage of fully connected MLP: difficult to detect local features. In fully connected neural network, we need a separate neuron to detect each of the items (same feature appear in different position). a waste of network parameters. Solution: using convolution to identify local features Advantages: fewer trainable params (sparse interactions) Same params reused multiple times (param sharing) translation invariance (equi-variance) 平移不变性 for continue: (f∗g)(t)=∫−∞∞f(τ)g(t−τ)dτ= ...

丹麦语 DU 3.1 Præsentation 1
教材 Undervisningsmaterialer På vej til dansk - trin for trin 纸质版一本 275 克朗,我们是教学机构借给我们用的,不能在上面写字。 这个 Synope 出版社的丹麦语教材的官网上有音频。可以自己跟着音频来练习。 电子版在 zlibrary 网站上能找到,就是版本有点老。 Præsentation 1 Hej, jeg hedder … 你好,我叫…… Hvad hedder du? 你叫什么名字? Alfabetet Aa “诶” Bb Cc Dd Ee “诶” Ff Gg Hh “乎” Ii “咦” Jj “哟” Kk “库” Ll Mm Nn Oo Pp Qq Rr “诶啊” Ss Tt Uu Ww “大步V” Xx Yy “於” Zz Ææ Øø Åå “唔” 丹麦语的发音 Udtale 太难了!!!感觉丹麦语也很喜欢像法语那样联诵 丹麦语的 Yy 相当于德语的 Üü 丹麦语的 Øø 相当于德语的 Öö Konjugation 在同一时态下的不同人称,没有动词变位 好耶:happy: Personlige ...
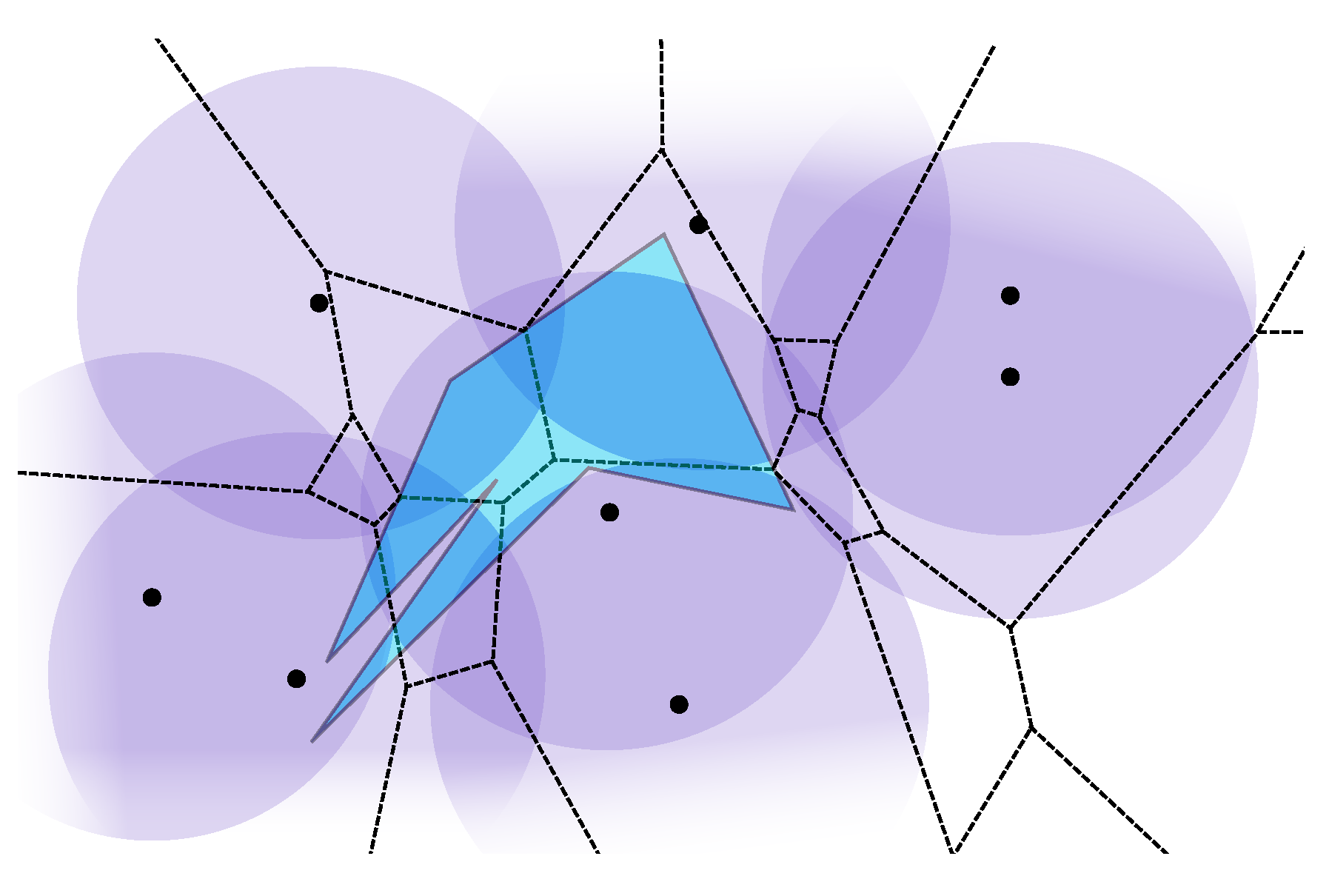
计算几何 W37 Sorting and Searching in Parallel
阅读材料 prefix sums and their application by Guy E. Blelloch, CMU parallel tasks: building blocks, and merge. dynamic programming & divide and conquer extended from sequential algorithms all-prefix-sums operation on PRAM intro prefix sum operation has many extension: quick-sort, lexical analysis, tree operations… primitive instruction in some machine(原子操作) define: scan operation is an array all-prefix-sums operation. implementation array length n, EREW PRAM, time complexity: O(n/p+log p) bi ...

算法博弈论 W37 Myerson's lemma
The most important course in AGT. Review Auction Sponsored search auction’s Goals DSIC dominant strategies, individual rationality. Social welfare maximization. Simplicity (w. r. t. complexity) design of single parameter mechanisms’ Goals: assuming participants report true preferences, maximize the social welfare incentives to the participants to report their true preferences. Myerson’s lemma Single Parameter environments env setup: n participants participant i has a non-negative private ...
计算机视觉 W37 Neural Networks
Decision boundaries motivation for non-linear transformation 在线性的 logistic 回归中,hw(x)h_w(x)hw(x) 大于 0.5 时认为是,小于 0.5 时认为不是 有的时候数据分布不适合使用逻辑回归模型(比如二维平面上一类包住了另一类) 简单采用 adding polynomial terms 的方法并不合适,需要泛化性更强的方法。 解决办法:神经网络 universal approximation theorem 用简单的台阶函数去拟合(?) Neural networks 人工神经网络 algorithm that try to mimic the brain SOTA AlexNet: bid data & GPUs perform well on many tasks artificial neurons aka perceptron y=1 if ∑i=1nwixi−θ≥0y=1\ if\ \sum_{i=1}^nw_ix_i-\theta\ge0y=1 if ∑i=1nwi ...
丹麦语 danskuddannelser 简介
在🇩🇰免费学丹麦语 根据丹麦当局当前的(2023 年)规定,所有非丹麦国籍的人只要是合法居留的,在首次登录丹麦五年内,享有免费受丹麦语教育的权力。 免费? 在某些指定的丹麦语教育机构,需要缴纳报名所需的押金,2000 DKK。在规定的时间段内通过该项 modul 考试就没问题。通过该项考试后:如果停止丹麦语学习,可以退还押金;如果想继续进行丹麦语学习,就可以不退押金继续下一个 modul。 Danskuddannelser 的不同级别 Danskuddannelser 有三个级别,分别为 DU 1,DU 2 和 DU 3。 DU 1 是给小孩学的,全部学完了大概能差不多到 B1 的水平(对应考试 Prøve i Dansk 1) DU 2 是给中学生(和没有参加过大学教育的人)学的,6 个 modul 学完了大概能有 B1 ~ B2 的水平(对应考试 Prøve i Dansk 2,丹麦永居要求必须通过这个等级及以上的考试) DU 3 是给大学生学的,一共 6 个 modul,前 5 个 modul 学完了大概能有 B2 的水平(对应考试 Prøve i Dan ...
计算几何 W36 Introduction to Parallel Computation
阅读材料 Parallel Algorithms by Guy E. Blelloch and Bruce M. Maggs Selected topics from (Sec. 1 and 2.1) Modeling parallel computations sequential algorithm: a single processor connected to a memory system (RAM) parallel computations: more complicated - requires understanding of the various models and the relationship among them two classes of parallel models multiprocessor n processors, shared memory three types multiprocessor models: local memory machine model each processor can access ...
算法博弈论 W36 Mechanism design basics
会在笔记中记录 Ιωάννης 的搞笑希腊口音的英语 帕拉漏 parallel 显仙秀里 essentially 神拿里欧 scenario 珠 true 多大儿 total 度 two Auction single-item auction sponsored search auction Single-item auctions Scenario a seller wants to sell an item n potential buyers (interested in the item, ready to act strategically to get it) Question: how do we design how the item should be sold? Intermediate problem: what do the buyers want? buyer i has no-negative val viv_ivi of the item valuate is private, unknown to other potential buyers ...
计算机视觉 W36 Machine Learning fundamentals
Linear regression goal: build a model take a vector X as input and predicts the output Y. Output is a linear function of the input Model and loss function model: hw(x)=∑j=1mwjxj=wTxh_w(x)=\sum_{j=1}^mw_jx_j=w^Txhw(x)=∑j=1mwjxj=wTx find a choice of w s. t. hw(x(i))h_w(x^{(i)})hw(x(i)) is as close as possible to y(i)y^{(i)}y(i) search for w that minimizes the L2 norm: loss function: J(w)=12∑i=1n(hw(x(i)−y(i))2=12(wTx(i)−y(i))2J(w)=\frac{1}{2}\sum_{i=1}^n(h_w(x^{(i)}-y^{(i)})^2=\frac{1}{2}(w ...
计算几何 W35 Introduction to Algorithm Engineering
课程简介 计算几何:理论和实验,aka Computational Geometry: Theory and Experimentation Week 35 - Week 49,共 14 周(除去秋假一周) 每周都有阅读材料,简单记录一下课前阅读笔记。 第一周(Week 35)内容:Introduction to Algorithm Engineering 阅读材料 Sanders title: Algorithm Engineering – An Attempt at a Definition by Peter Sanders (Universität Karlsruhe) Algorithm engineering: cycle of design, analysis, implementation, experimental evaluation. algorithm engineering = experimental algorithmics??? too limited design: not just care about asymptotic worst effi ...


