
“一生一芯”计划 基础阶段
“一生一芯”计划——基础阶段实验报告
基础阶段(B 阶段)的目标
- 在自己设计的处理器上运行红白机游戏《SUPER MARIO BROS.》
- 深入理解《SUPER MARIO BROS.》是如何在自己设计的处理器上运行的
基础阶段(B 阶段)的大致步骤
- 搭建基础设施(提升调试效率的工具和方法)。
- 设计一个支持 RV64IM 的单周期处理器。先实现一个 RV64IM 的模拟器,在不接触RTL实现细节的情况下理解RISC-V指令和程序的行为, 然后再把这些理解迁移到RTL实现的真实处理器中。
- 为单周期处理器添加输入输出功能。B 阶段暂时不引入总线,而是借助仿真环境为处理器提供输入输出功能。
简易调试器(2022.7.15~2022.7.17)
在预学习阶段完成了 PA 1.1,此阶段需要完成 PA 1 剩下的内容 PA 1.2 和 PA 1.3。
PA 1.2 表达式求值
实现算术表达式的词法分析
学过编译原理,但是基本上知识全还给老师了(((
实现此处的词法分析,先分析表达式需要的所有 token。根据实验指导书分析,token 不同类型的优先级从上到下为:
- 解引用、负号
- 乘法符号、除法符号
- 加法符号、减法符号
- 等于、不等于、大于等于、小于等于、大于、小于等判断大小的符号
- 逻辑与符号
- 逻辑或符号
此外还要能识别 token。此处实现了十进制和十六进制的 token 识别。识别 token 是使用正则表达式进行匹配~~(复习一下编译原理了)~~。将识别出的 token 存到 tokens 数组中。
实现算术表达式的求值
此处没有使用指导书上的递归求值过程。而是使用 符号栈—数据栈 的方式进行表达式的求值。
具体思路如下:
在符号栈中压入一个终结符
依次扫描 tokens 数组
如果扫描到的是数字或寄存器
- 针对数字:调用实现的 str2int 函数,支持十六进制或十进制的数字的字符串转为 int 类型,并将这个 int 值压入数据栈中
- 针对寄存器:遍历所有寄存器名称,比对寄存器名和当前 token 对应字符串,如果成功匹配,将该寄存器对应的值压入数据栈中
如果扫描到的是运算符。首先针对所有的运算符设计了一个优先级表格。查找该表格,可以得到符号栈顶的符号和当前 token 符号的优先级大小。
在判断优先级之前,由于实现了解引用和符号的功能,需要先处理这几种特殊情况
判断如果前一个 token(
token[i-1])也是符号:- 如果识别出符号为 ‘-’,则当前符号会被认为是负号
- 如果识别出符号为 ‘*’,则当前符号会被认为是解引用
如果栈顶符号优先级小于当前符号,直接将当前符号压入栈中
如果栈顶符号优先级大于当前符号,将栈顶符号弹出,连续从数据栈中弹出运算符需要个数的数据值,进行运算后,将结果压入数据栈中
如果栈顶符号优先级等于当前符号(对应到的是左右括号的匹配),直接将符号栈顶的符号弹出即可。
如果栈顶符号优先级无法与当前符号比较,只能说明输入的表达式有误。
实现表达式生成器
在 nemu/tools/gen-expr/gen-expr.c 中实现。
表达式的 CFG 定义比较简单:(expr 为起始符号)
(梦回编译原理)
使用随机数原理,在随机生成数字、符号时调用空格生成函数按一定概率随机生成空格。
PA 1.3 监视点
扩展表达式的求值功能
直接在前面实现了扩展表达式的求值功能。此处略。
实现监视点池的管理
通过 RTFM 和 RTFSC 可知:监视点池通过链表来实现。
链表结构体中新增两个成员:64 位整型变量 old 表示当前监视点的值,字符指针变量 expr 表示当前监视点的表达式。
增:新增监视点时,从
free_链表中取出一个节点,加入到监视点的链表中。在cmd_w函数中对该节点进行赋值。删:删除监视点时。先得从链表中找到要删除节点:从头开始遍历监视点链表,检查编号 NO 是否匹配输入编号,若匹配则在链表中删除该节点。
打印:直接从头到尾遍历监视点链表,分别打印具体内容即可。
检查:从头到尾遍历监视点链表,计算字符串表达式的值,与
old变量进行比对。
实现监视点
根据实验手册提示,将监视点的值是否有变化检查操作放在 trace_and_difftest() 中。使用一个新的宏 CONFIG_WATCHPOINT 将代码包括。
然后在 nemu/Kconfig 中为监视点添加一个开关选项, 最后通过 menuconfig 打开这个选项, 从而激活监视点的功能。
PA 1 必答题
程序是个状态机
程序 1+2+...+99+100 的程序的状态机如下:
graph LR s((start:0,x,x)) 0((1,0,x)) 1((2,0,0)) 2((3,0,1)) 3((4,1,1)) 4((2,1,1)) 5((3,1,2)) 6((4,3,2)) t0((5,5050,100)) t1((4,5050,100)) t2((3,4950,100)) t3((2,4950,99)) t4((4,4950,99)) t5((3,4849,99)) t6((2,4849,98)) mid[...] mid1[...] s-->0 0-->1 1-->2 2-->3 3-->4 4-->5 5-->6 6-->mid t0-->t0 t1-->t0 t2-->t1 t3-->t2 t4-->t3 t5-->t4 t6-->t5 mid1-->t6
估计调试花费的时间
编译 500 次,其中 90% 用于调试,平均 20 个信息排除一个 BUG,平均每 30 秒获取并分析一个信息。
一共需要
而使用简易调试器可以节约
RTFM:ISA 手册
一生一芯计划选择的式 RISC-V64 的 ISA。
RISC-V 有哪几种指令格式?
有 R,I,S,B,U,J 六种基本指令格式。

LUI 指令的行为是什么?
指令手册上的原文:
LUI (load upper immediate) is used to build 32-bit constants and uses the U-type format. LUI places the 32-bit U-immediate value into the destination register rd, filling in the lowest 12 bits with zeros.
将 20 位常量加载到 寄存器的高 20 位,寄存器的第二十位置为 0。
mstatus 寄存器的结构是怎么样的?

shell 命令:统计代码量
nemu/目录下的所有 .c 和 .h 和文件总共有多少行代码?
采用的 shell 命令为:
find . -name "*[.h|.cpp]" | xargs wc -l。使用上述命
令,得到nemu/目录下的代码一共有 24250 行。
RTFM:gcc 编译选项
gcc 中的 -Wall 和 -Werror 有什么作用? 为什么要使用 -Wall 和 -Werror?
-Wall使gcc产生尽可能多的警告信息,取消编译操作,打印出编译时所有错误或警告信息。-Werror要求gcc将所有的警告当成错误进行处理,从而终止编译操作。- 使用
-Wall和-Werror就是为了找出所有存在的或者潜在的错误,以便于优化程序。
PA 1 到此结束 🎆🎆🎆
支持 RV64IM 的 NEMU(2022.7.17~2022.7.20)
(完成 PA 2.1 用 C 语言实现一个 RISC-V 64 的处理器模拟器)
完成要求:在 NEMU 中成功运行目录 cpu-test 下除了 string 和 hello-str 之外的所有 C 程序。
不停计算的机器
取值(IF)→译码(ID)→执行(EX)→更新 PC
RTFM&RTFSC:理解指令执行的过程
IF 取指阶段
连续嵌套调用了好多函数 inst_fetch()->vaddr_ifetch()->paddr_read()
最终本质上就是访问一次内存。
ID 译码阶段
进入译码阶段,调用函数 decode_exec() 。在该函数中,使用了好多宏,对应宏里面也有调用好多其它的函数,需要仔细分析。
宏展开后,发现就是调用译码阶段的匹配操作、一系列操作数译码的代码被解耦封装成一个个的 API。
EX 执行阶段
执行阶段已经将值记录到对应的操作数中,需要调用 API 将对应的操作数放回到目标寄存器中。
更新 PC
在 decode.h 中定义的 snpc 和 dnpc 区别:
- snpc 指的是代码的下一条指令
- dnpc 指的是程序运行过程中的下一条指令
在更新 PC 时,使用的是 dnpc。
准备交叉编译环境
由于 YSYX 采用的是 RISC-V 的 ISA,因此需要
1 | apt-get install g++-riscv64-linux-gnu binutils-riscv64-linux-gnu |
配置交叉编译编译环境
运行第一个客户程序
RTFSC 和 RTFM 之后,在 NEMU 的 inst.c 中添加指令。
在 cpu-test 目录下通过命令 make ARCH=$ISA-nemu ALL=dummy run 尝试在 NEMU 中运行指令 dummy 程序。会显示 The instruction at PC=???? is not implemented.
根据此处的 pc 值在反汇编文件中找到对应的指令。再将指令展开成二进制的形式在 RISC-V 手册中进行查找。
运行 dummy 程序需要添加的指令是:
添加完这三条指令后,可以成功在 NEMU 中运行 dummy 程序了。
实现更多的指令(指令具体信息待补充!)
运行 add 程序
需要添加的指令为:
lw指令addw指令sub指令sltiu指令(可实现伪指令seqz)beq指令bne指令addiw指令
正确实现以上指令后,就能成功运行 add 程序了。
运行 add-longlong 程序
需要添加的指令为:
add指令
运行 bit 程序
需要添加的指令为:
sb指令srai指令lbu指令andi指令sllw指令and指令sltu指令(可实现伪指令snez)xori指令or指令
正确实现以上指令后,就能成功运行 bit 程序了。
运行 bubble-sort 程序
需要添加的指令为:
slli指令srli指令bge指令sw指令
运行 div 程序
需要添加的指令为:
mulw指令divw指令
运行 fact 程序
运行 fib 程序
运行 goldbach 程序
需要添加的指令为:
remw指令
运行 if-else 程序
需要添加的指令为:
blt指令slt指令
运行 leap-year 程序
运行 load-store 程序
需要添加的指令为:
lh指令lhu指令subw指令sh指令
运行 matrix-mul 程序
运行 max 程序
运行 min3 程序
运行 mov-c 程序
运行 movsx 程序
需要添加的指令为:
slliw指令sraiw指令
运行 mul-longlong 程序
需要添加的指令为:
mul指令
运行 pascal 程序
运行 prime 程序
运行 quick-sort 程序
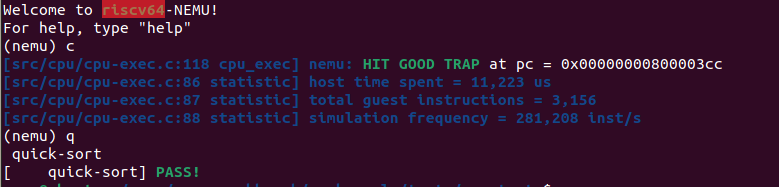
运行 recursion 程序
需要添加的指令为:
lui指令
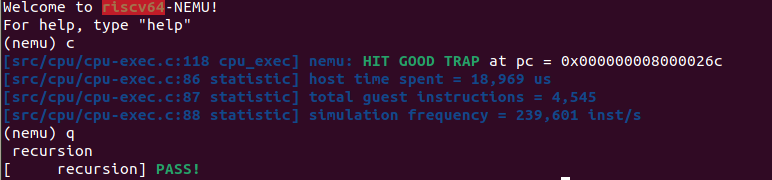
运行 select-sort 程序
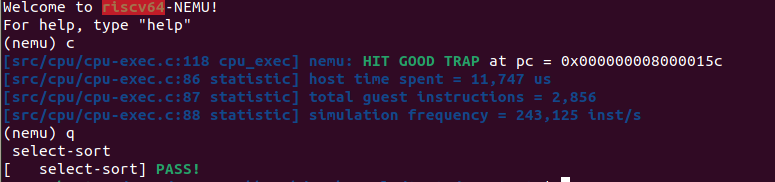
运行 shift 程序
需要添加的指令为:
srliw指令sraw指令srlw指令
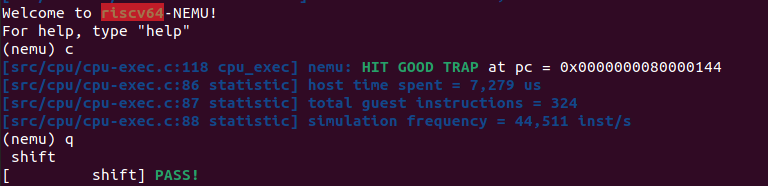
运行 shuixianhua 程序
运行 sub-longlong 程序
运行 sum 程序
运行 switch 程序
需要添加的指令为:
bltu指令
运行 to-lower-case 程序
运行 unalign 程序
运行 wanshu 程序
PA 2 阶段 1 到此结束🎆🎆🎆
用 RTL 实现最简单的处理器(2022.7.21~)
尝试通过 RTL 代码实现一个最简单的处理器
RTL 项目模块划分:取值单元 IFU、译码单元 IDU、执行单元 EXU、更新PC
用 C++ 实现存储器。
运行时环境 和 基础设施(2)(2022.7.25~)
(完成 PA 2.2)
AM = TRM(图灵机) + IOE(输入输出扩展) + CTE(上下文扩展) + VME(虚拟内存扩展) + MPE(多处理器扩展)
修改 Makefile 使得 NEMU 启动后可以自动运行客户程序
NEMU 中已经实现好了批处理模式,但是需要传入参数 -b 才能开启该模式。因此需要找到 Makefile 在何处传入该参数。
根据 Makefile 的相关文档和调试之后得到的信息,最终锁定在 nemu.mk 中,仿照 NEMUFLAGS += -l $(shell dirname $(IMAGE).elf)/nemu-log.txt,添加一行 NEMUFLAGS += -b。之后再在 cpu-test 下测试,就能发现 NEMU 默认自动开启批处理模式运行了。
(在这里我卡了很久,当浏览论坛发现了相似的帖子之后就清楚了)
一键测试确实很爽!
实现字符串处理函数
在 abstract-machine/klib/src/string.c 中实现和字符串有关的函数:
- 字符串相关:strlen(求字符串长度)、strcpy(copy 字符串)、strncpy(copy 字符串的前 n 个字符)、strcat(拼接字符串)、strcmp(比较字符串字典序大小)、strncmp(比较字符串的前 n 个字符的子串字典序大小)
- 内存相关:memset(按字节设置内存)、memmove(复制某段内存前 n 个字节到另一段内存,可允许有重叠部分)、memcpy(复制内存,不允许重叠)、memcmp(按字节比对内存)
完成之后到 cpu-test,测试 string.c 样例(make ARCH=$ISA-nemu ALL=string run),发现成功运行改测试样例。
实现 sprintf
先添加 rem 指令、div 指令、bgeu 指令
再实现 sprintf 函数。
sprintf 函数的意思是:将格式化的数据写入字符串。通过 RTFM 得知可以使用 vsprintf 来实现 sprintf。
vsprintf 里面进行判断是否有 %s 或 %d 的转义。如果遇到数字,需要将数字转换为字符串,此时需要添加一个辅助函数 char *n2s,此函数功能为将数字 n 以 base 进制转化为字符串到 s,并且返回字符串 s 的末尾位置。
运行 cpu-test 下的 hello-str 程序,发现结果正确。
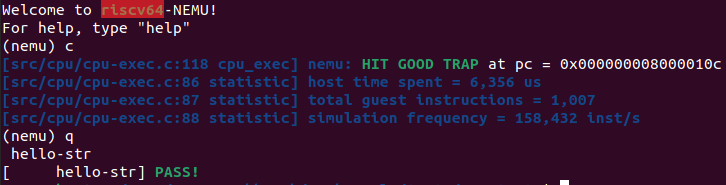
实现 iringbuf
iringbuf 是在已经实现 itrace (instruction trace) 的基础之上希望能打印出最近执行的若干指令。
在 RTFSC 之后,发现应该在 cpu-exec.c 中实现 iringbuf。
1 |
|
在 trace_and_difftest 中在进行 log_write 写入 itrace 到 log 之后,将当前执行写入到 itracebuf 数组中的操作。
当程序停止时(对应代码在 cpu_exec 最后的 switch),遇到 NEMU_END 或是 NEMU_ABORT,打印出程序停止相关程序信息之后调用该函数 print_iringbuf(只输出一次)。
此时假设程序在执行过程中出现了问题,在停止时就能输出程序出错之前最近执行几次指令。
实现 mtrace
mtrace (memory trace),顾名思义是追踪程序的访存行为。
只需要在 paddr_read() 和 paddr_write() 中进行记录。
并在 Kconfig 中添加相应控制宏定义的代码,以达到方便开关的目的。
此外在 sdb.c 中的 cmd_table 中添加一条打印 itrace 或 mtrace 的命令,提高了 NEMU 单步调试的效率。
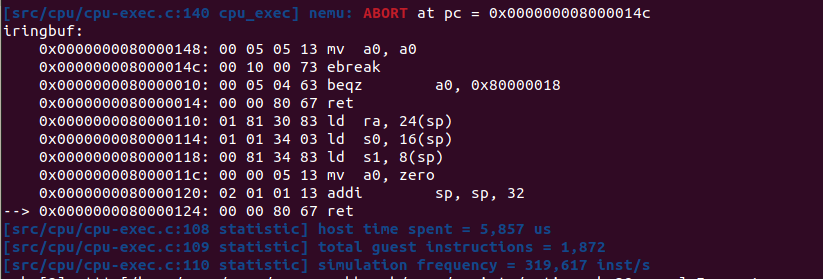
实现 ftrace
为了了解程序的语义行为,用于追踪程序执行过程中的函数调用和返回。
只需要关心函数调用和返回相关指令。
在 cpu-test/build 下使用命令 riscv64-linux-gnu-readelf -a add-riscv64-nemu.elf 查看 ELF 可执行文件的信息。
为了专门用于操作 ELF 文件,在 nemu/src/util/ 下创建一个 elf.c 源代码文件。
ELF 头
ELF Header 在 ELF 文件的最开始,只需要从文件最初地址(0偏移)顺序读取大小为 sizeof(Elf32_Ehdr)的数据即可。
读取函数可以通过下面函数实现
1 | fseek(elf, offset, SEEK_SET); |
在 ELF Header 中关于 Section Header 的信息
1 | elf_header.e_shoff; // 节头表相当于 elf 文件的偏移 |
根据此能够确定 Section Header 在 ELF 文件的具体位置,Section Header 有许多表项:
1 | Section Headers: |
其中,由于每个 Section Header 的大小是固定的,而它们的名称属性不可能一样长,所以需要一个专门的 string section 来保存它们的名称属性。
根据 ELF 的手册内容可知,在 Section Header 部分信息
1 | typedef struct |
sh_name就是该节的名称在.shstrtab的索引:.strtab,.symtab这些名称信息就通过sh_name在.shstrtab找到。sh_type,对于找到.symtab(类型是SYMTAB)和.strtab(类型是STRTAB)至关重要sh_offset和sh_size分别为该节在 ELF 文件的位置偏移的大小sh_entsize表中的每个 entry 的大小,比如在.symtab中还有许多子entry,可以用sh_size/sh_entsize求出条文数目
符号表和字符串表
遍历 Section Header 中的每个表项 Elf64_Shdr section_entry,找到 section_entry.sh_type = STRTAB 和 STRTAB,就能找到符号表 .symtab 和字符串表 .strtab。
注意:.shstrtab的类型同样也是STRTAB,不过根据上面的内容应该能加以区分。
扫描 .symtab 找到 ELF64_ST_TYPE(table_sym[i].st_info) == STT_FUNC 其中
st_name:函数名称在.strtab中的偏移st_value:虚拟地址(可执行文件中表示虚拟地址;可执行目标文件中表示数据所在节的偏移)st_size:函数大小
至此已经完成预先处理函数表的过程。
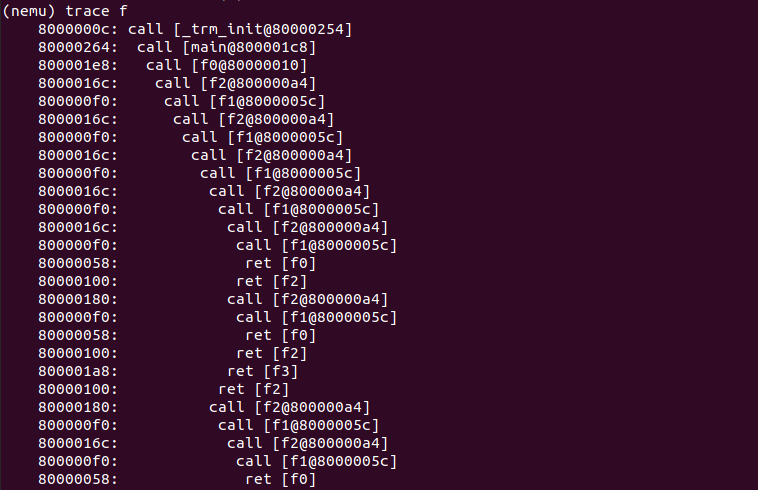
FTrace 完成之后的效果如下,和实验指导书上对比无误。
测试自己实现的 klib
(待添加内容)
实现 DiffTest
RTFM & RTFSC
填写 nemu/src/isa/riscv64/difftest/dut.c 中的 isa_difftest_checkregs 函数。很简单,就比对 pc 和 cpu 里边对应的寄存器值是否相等即可。
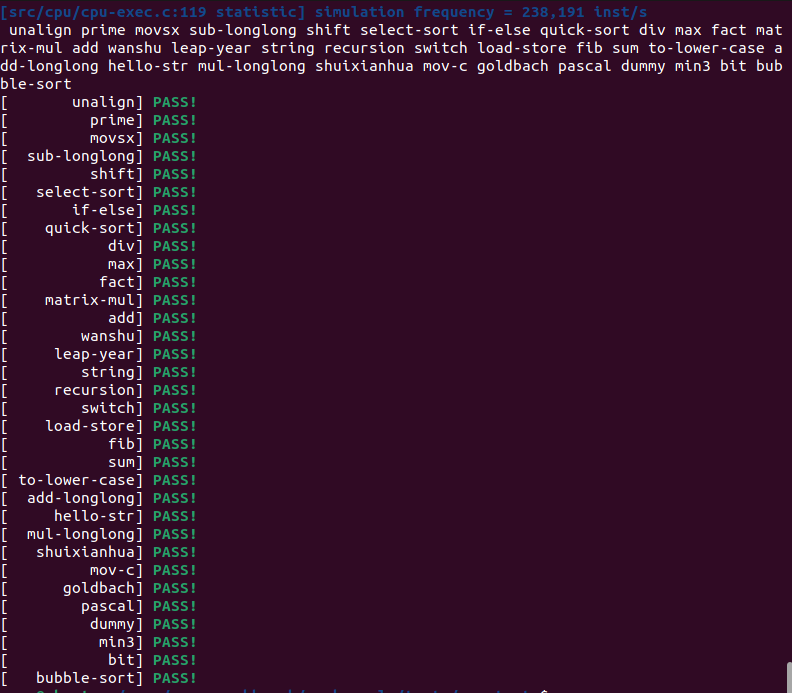
一键回归测试
要在打开 Difftest 的情况下运行一键测试,需要下载 Spike:apt-get install device-tree-compiler,并且到 spike-diff 去 make 一下。
最终在打开 itrace、ftrace、mtrace、difftest 时,一键回归测试能通过所有样例。
(PA 2.2 到此结束)
支持 RV64IM 的单周期 NPC
设备和输入输出
没时间,😭半😭途😭而😭废😭了😭


